The Missing Ingredient in Loop Engineering: Observability
Everyone's talking about loop engineering: automations, worktrees, sub-agents. They all skip the ingredient that makes letting agents run for days safely: observability.

Recently, Anthropic launched its Fable/Mythos line of superautonomous coding models. These new models have demonstrated significant leaps in capability (specifically agentic coding tasks) and far greater autonomy than we’ve seen before. Take a look at what we’re talking about here; the magnitude of improvement over Opus is astounding.
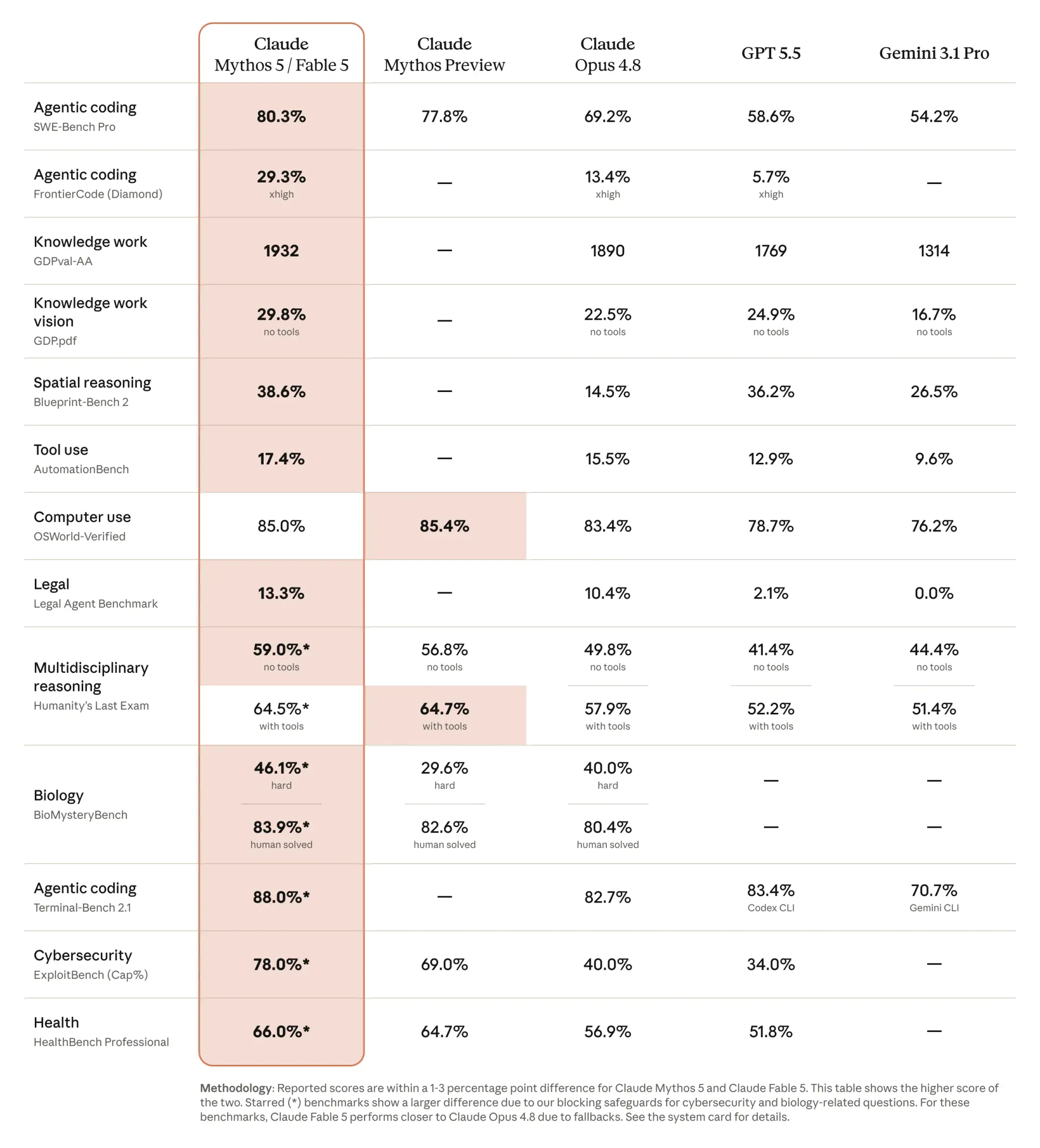
However, these new capabilities are costing us roughly 2x the token cost of the existing frontier models (Opus 4.8, as of June 2026), and they ship with significant safety guardrails that clearly need continuous refinement. Microsoft has halted the rollout of Fable internally, citing “data retention concerns.” Regardless, it’s impossible to deny this is a major leap for coding agents. Mike Krieger said it well:
With earlier models, you broke a project into model-sized tasks and stitched the results together. Fable holds the whole project. It plans, runs for hours or days, checks its own work, and comes back when it’s done.
Must be nice to have access to infinite token spend. I’m pretty sure even the Max 20x plan would be exhausted within a 24-hour span. Either way, “comes back when it’s done” only holds up if you can trust what it did while you weren’t watching. Hold onto that thought; it’s the whole reason for this essay.
Vibe Coding Is OVER. We’re Loop Engineers Now!
The launch of these new models happened to coincide with the recent “loop engineering” zeitgeist, which has kicked off waves of discourse centered on the never-ending question of “Are we holding AI right?” If you aren’t familiar with what I’m talking about, check out this talk with Boris Cherny.
“I don’t prompt Claude anymore. I have loops running that prompt Claude and figure out what to do. My job is to write loops.” – Boris Cherny
Similarly, this sentiment was more recently echoed by the creator of OpenClaw, Peter Steinberger:
I’ve also found myself trending in this direction for the past quarter on a major project Limbic Systems is launching publicly soon. I think this realization is hitting a lot of folks independently at the same point in their agentic coding adoption curve, because we’re beginning to trust this technology far more than we did even a year ago. We’re letting go of more and more control and opinionation, and as a result, we’re trusting the models to make more decisions.
In my own experience, I find myself focusing instead on clarifying success criteria, systematizing workflows and processes, and orchestrating task delivery. For the astute reader, you may have noticed that these are the tasks engineering managers and directors have historically been responsible for.
Yes, folks, that’s right: what if I told you engineering managers were just loop engineers this whole time?

Is It a Loop or an Arc?
Addy Osmani’s blog post on loop engineering does a great job of articulating the “mise en place” of loop engineering, and identifies the critical ingredients you should be reaching for:
- Automations that go off on a schedule and do discovery and triage by themselves.
- Worktrees so that two agents working in parallel don’t step on each other.
- Skills to write down the project knowledge that the agent would otherwise just guess.
- Plugins and connectors to plug the agent into the tools you already use.
- Sub-agents, so one of them has the idea and a different one checks it.
- Memory that acts as a repository and ledger of contextual knowledge being built, curated, and accessed across subsequent sessions.
I agree with all of these. I rely on them daily to let Opus 4.8 run for hours at a time, freeing me up to write essays like this. But notice what these ingredients have in common: every one of them pushes work forward. They start the loop and keep it spinning. None of them inherently advance the loop to converge on a successful outcome and may just spiral in place (I've seen this firsthand, too. It's an expensive mistake).
That’s the difference between a loop and an arc. An arc has a default end state you can recognize and resolve toward (sometimes I hear this mentioned as a “goal”). If we want a true loop, we must integrate feedback. There are many forms of feedback we can reach for (code review feedback is an obvious good example). I posit the critical component missing from every one of these lists is the feedback that keeps the work cycling instead of dead-ending as an arc: Observability.
Building Trust With Observability
As a Xoogler, I was observability-pilled early in my tenure there. We instrumented nearly everything we could safely observe to build trust about how systems actually behaved in production against real production traffic. This made feature rollouts safer, made resource planning easier, and was the backbone of large-scale continuous delivery for my teams.
Returning to the premise that we might let models like Fable run for days uninterrupted, I find it strange how rarely I hear about the role observability must play for this to work; maybe it’s getting conflated with other feedback signals (I hope so).
Observability has always been central to building system trust. In fact, the late USAF strategist John Boyd built an entire combat decision process around exactly that: the OODA Loop.

The four stages map almost perfectly onto a long-running agentic process.
- Observe: the telemetry the system emits about its own behavior.
- Orient: grounding those observations against memory, skills, and prior context.
- Decide: choosing the next action from that grounded picture.
- Act: shipping the change, then feeding the result back into the next Observe.
This was precisely how I ran large engineering teams and projects at Google, and it’s how my swarm of agents runs now.
How I’m Implementing Observability With Coding Agents
Luckily, many of the techniques I used at Google are available to us mere mortals. Specifically, I reach for the OpenTelemetry SDK. As a standard, it provides every affordance you need to instrument almost any system (counters, gauges, histograms, and so on), plus a standardization for tracing and structured logging. Coding models are very good at implementing this triad, so your system can throw off a ton of incredible production diagnostics with very little effort.
Telemetry emission is great, but it has to go somewhere to be useful to humans and AI alike. My go-to tool is Prometheus, though I’m currently enamored with Grafana Cloud as a platform (ps: I am not affiliated with them, I just love what they do). Their platform absorbs all of my telemetry and makes it available to my coding agents via MCP. Exposing a read-only MCP endpoint means my agents can develop a PR, instrument it, push it, and then observe actual production behavior within the development loop, without ever leaving the session.
Doing things this way has quickly rewired how I approach agentic development. At first, I scrutinized every PR an agent produced, hunting for bugs and logic errors before rolling out its commits. However, with this level of instrumentation and access, I can let the agent iterate and empirically observe the impact of a change to validate it, with no involvement from me at all (just kidding; I still skim these PRs for egregious errors).
Closing the Loop
Observability inside a single task cycle has dramatically improved autonomous acceptance criteria. With this approach and these systems in place, we can squeeze out even more value through two key mechanisms.
- Commit and push reconciliation for Grafana, using the gcx CLI tool and a little GitHub Actions magic. This (along with agent skills) lets Opus build a relevant dashboard for me and configure the critical notification thresholds that should be monitored in production.
- Grafana notifications triggering agentic Incident Responders, using Grafana’s Contact Points. With this, we can trivially fire a Claude Code Routine off a webhook POST, activating a continuously evolving runbook of operations and diagnostic steps that can either self-heal or page me to intervene.
I've already implemented the commit and push reconciliation, and it's been really great. Opus can review the available metrics in the codebase and keep my dashboards in sync in a single PR. I've yet to establish the incident response triggers, mainly because I believe that's going to require some additional coordination work if there are many agents responding/reacting to a cascade of notifications. That's next on my horizon to explore.
Before you decide I’ve lost my fucking mind here, keep in mind that the requisite defense in depth and systems hardening (strict backups, least-access principles, and the rest) are a must before extending this level of trust to autonomous agents. My counterargument is simply that all of this was already necessary with human counterparts.
I’m embracing the loop because it’s a natural evolution of a battle-tested approach I’ve leaned on for nearly my entire career in software engineering, both as a practitioner and as a director. None of this is new. If anything, it’s encouraging to watch these lessons live on in the agentic era, stronger than ever.
If this is the kind of thing you want more of, Better Questions goes out free. Subscribe, and I’ll send the next one straight to your inbox.
About the author

Derek Perez is the Founder & Principal Technologist of Limbic Systems, a software consultancy that partners with organizations to design and deploy AI-native software and systems, without losing the human judgment that keeps them grounded. After over a decade of hands-on experience building startups and leading high-performing teams at Google, he partners with founders and operators who need both technical depth and business acumen to navigate what's next. Find him on LinkedIn and Bluesky, or by email: derek@limbic.systems.