Help Agents Help Themselves: Orchestration Patterns That Make Failure Cheap
Niels Bantilan's talk at Coding Agents 2026 reframes the agentic reliability problem: we obsess over semantic correctness, but production failures often live in the infrastructure layer. Here's what durable agent design actually looks like.
The most revealing moment in Niels Bantilan's talk wasn't about agents at all. He asked the room who'd installed OpenClaw; a handful of hands went up. Then: “Who’s willing to install it on their company infrastructure?” The room nervously let out a laugh.
That gap between what works in dev and what runs reliably in production is exactly what Niels has been building toward for the last five years. Niels Bantilan spoke at the Coding Agents 2026 conference in Mountain View, CA. He’s the Chief ML Engineer at Union.ai and the creator of Flyte, the open-source ML orchestration platform running in production at LinkedIn, Stripe, Spotify, and Mistral. His talk, “Decomposing the Agent Orchestration Ecosystem,” wasn't a product pitch in my view; it was a practitioner’s field report on what breaks in agent systems and, more importantly, how to design for the inevitable and what capabilities that unlocks with it.
The infrastructure problem
Here’s the trap most agent builders fall into: we invest heavily in semantic correctness: evals, prompt engineering, context window management, to name a few. As I’ve written about in this series on evals, these are real and important problems. But Niels' talk introduces an entirely new failure category sitting below all of that: infrastructure failures that almost no eval harness actually tests.
Tools require secure, least-privilege access. Agents engaged in meaningful ML tasks need variable compute resources. Containers run out of memory, spot instances get preempted, and when any of that happens, agents lose context. Not the logical context you carefully engineered, but the State. The hard-won intermediate outputs from many prior steps are lost.
The problem isn’t that agents fail; this should be expected. It’s that recovering from failure is challenging without the full context of how infra, networking, logical, and semantic layers all interact.
His key insight: agents actually can recover from all of these failure modes, including infrastructure-level ones, but only if you can preserve their context and provide the capabilities to dig themselves out.
Durability as a first-class design principle
Niels distills the answer into three core building blocks that Flyte implements, but that any serious orchestration stack should think about:
Replay logs are per-run, granular records of every step an agent takes and its output. If an agent runs 200 steps and fails on step 147, a replay log means it picks up at step 147, not step 1. Think build caching, but at the agent-run level.
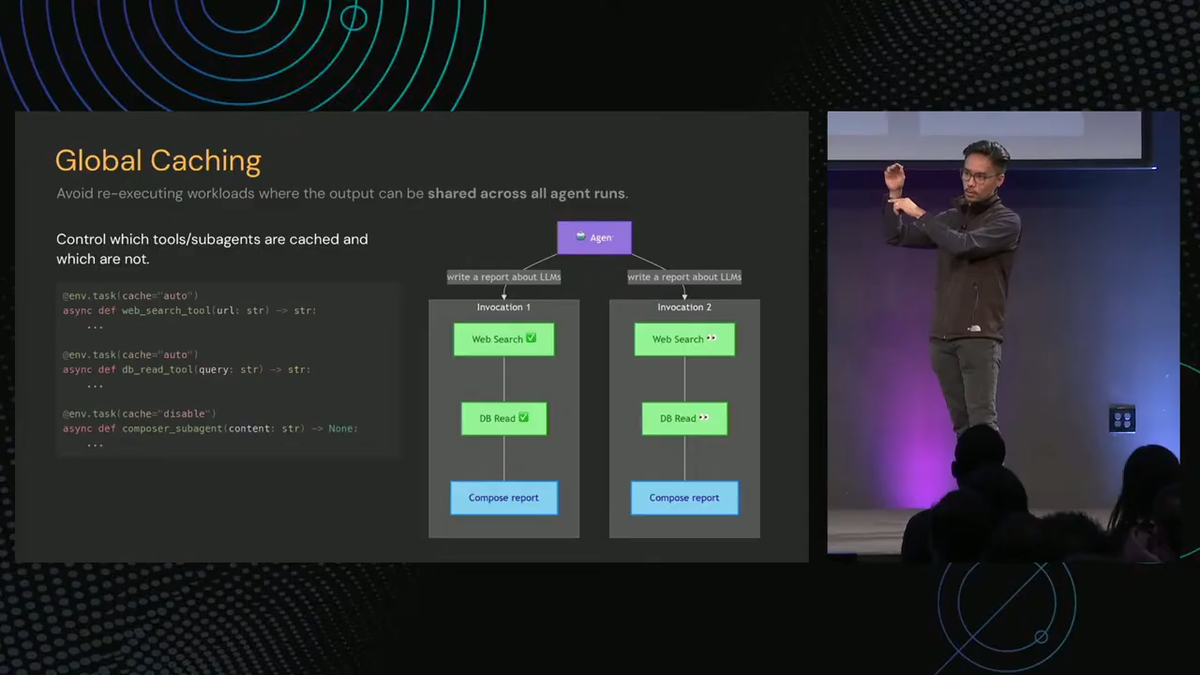
Global caching is shared across all agent runs. If two research threads hit the same web search or database query, pay for it once. One of Niels’s customers built semantic convergence detection into their coordinator layer, collapsing duplicate research threads before they could do redundant work.
Intermediate state persistence means every LLM call and tool result is automatically serialized to object storage. You don’t write serialization code. Data lineage comes as a side effect.
These aren’t exactly new ideas. They’re the same primitives we expect for ETL and ML pipelines, applied to agentic workflows. The insight is that the agent context problem is partially the same old infra problem we're used to, don't forget it!
Six design principles that actually compose
Niels walked through six rules of thumb for building agents on this foundation. The three I found most practically useful:
Use plain Python (or TypeScript, or whatever a capable LLM already knows). No DSL surprises. No new constructs for either the human or the agent to learn. The important corollary: exceptions become a first-class delivery mechanism for failure context. An out-of-memory error surfacing as a Python exception can be caught, reasoned about, and responded to by the agent in a processing loop.
Make failures cheap. Don’t aim for failure-proof. Aim for fast recovery and tight feedback loops. This is a mindset shift as much as an architecture choice; the goal is cheap retries, not zero failures.
Infrastructure as context. This is the framing I hadn’t seen articulated clearly elsewhere. If an agent can observe infrastructure-level errors (not just tool call failures but OOM errors and spot instance preemptions), it can respond to them. Niels showed code where an agent catches an OOM, reasons about it, and provisions more compute for a training job. The agent isn’t just retrying. It’s self-correcting.
Sandboxes and human recourse
One section I found genuinely novel: Niels distinguishes two types of agent sandboxes. "Code mode" (which I've also written about) replaces tool call formatting with actual Python: the agent writes code to call its tools rather than formatting JSON arguments. This reduces context bloat and creates a tight iteration loop for fixing orchestration bugs in a constrained and familiar domain, writing small scripts.
Stateless code sandboxes are broader; they may allow third-party imports and limited IO, operating as pure functions for one-shot tool execution. Agents can, in turn, write their own unit tests against these, shifting evals from an out-of-band process into something that happens in the inner reasoning loop in real-time.
And when all else fails, if the prompt is truly wrong or the agent is out of context, human-in-the-loop recourse is the final safety valve. Not a sign of system failure, but an architectural guarantee that there’s always an escape hatch.
The Dragonfly case study
Niels’s production example was Dragonfly, which built an automated solutions architect: an agent that maintains a living knowledge graph of ~250,000 SaaS products. Each product call involved ~200 steps and ~100 LLM calls. This runs ambiently and continuously, not as a chat interface.
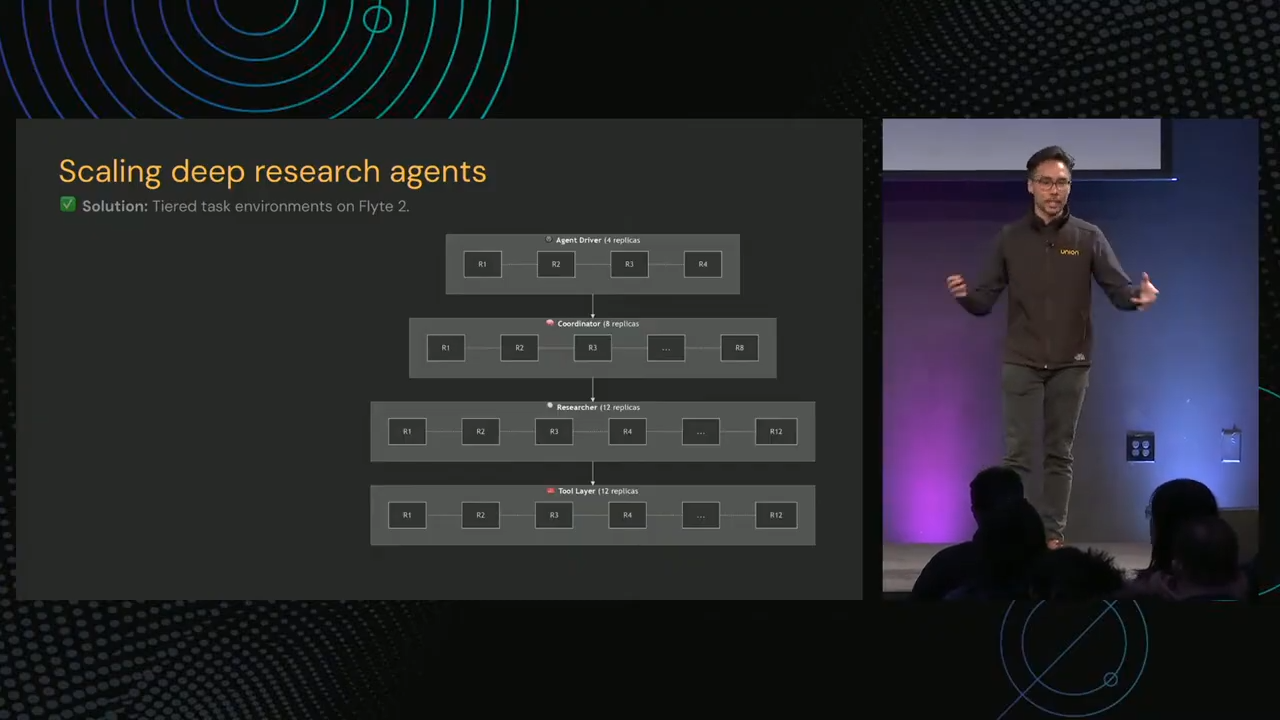
Their tiered architecture: 4 agent drivers → 8 research coordinators → 12 researchers → 12 tool replicas. Semantic convergence detection in the coordinator layer collapsed duplicate research threads. Spot instance failures became a non-issue with checkpoint-based recovery.
The results: 50% reduction in failure recovery time, 30% improvement in development velocity, 12 hours/week saved on infrastructure maintenance. Onboarding their local prototype to production took about an hour.
What struck me: this isn’t a novel architecture. It’s what we’d recognize from data engineering: workers, coordinators, caching, and fault tolerance. Agents are just running the workers now. The primitives transfer.
How I’m thinking about this
The framing sticking with me is the distinction between semantic correctness and infrastructure durability. Our evals test the former. We build recovery logic for the former. But the failures that actually kill production agent systems often live in the infrastructure layer, and we have a less eloquent vocabulary for testing them today.
Two questions I’m adding to my evaluation checklist: Does your eval harness test recovery from infrastructure-level failures, or only logical ones? And does your agent have access to its own failure context, or does each retry start blind?
The sub-agents-not-swarms pattern I wrote about from Pinterest’s experience maps cleanly here, too. Simpler hierarchies, tight isolation, cheap retries. The pattern across these talks is converging: less magic, more observability, and failures that cost you milliseconds instead of minutes.
What's next?
Watch Neils' full talk. If you're developing production agentic workflows, it'll be well worth your time to think about the concepts he presented in his talk. Maybe, even check out Flyte for yourself.
Watch Neil's full talk from Coding Agents 2026
About the author

Derek Perez is the Founder & Principal Technologist of Limbic Systems, a software consultancy that partners with organizations to design and deploy AI-native software and systems — without losing the human judgment that keeps them grounded. After over a decade of hands-on experience building startups and leading high-performing teams at Google, he partners with founders and operators who need both technical depth and business acumen to navigate what's next. Find him on LinkedIn and Bluesky, or by email: derek@limbic.systems.