Sub-Agents, Not Swarms: What Pinterest Learned Productionizing LLM Training With Coding Agents
The question of how to architect multi-agent systems for production workloads doesn't have a settled answer yet. Pinterest's Growth AI team tried both sub-agents and swarms for LLM post-training, and their results challenge some common assumptions.
Faye Zhang, a tech lead at Pinterest's Growth AI Applications team, gave a lightning talk at the Coding Agents 2026 conference in Mountain View, CA, that dug into what happens when using coding agents for LLM post-training in production, and the architectural choices that make the difference between a week-long pipeline and a six-week slog.
Whether you're developing an agentic CRM, a security threat-hunting product, or anything else that depends on a finely tuned model, you need that model aligned with what "good" actually means for your use case: the right reasoning, the right tool-calling behavior, the right persona. Achieving this is often a slow, manual process. Faye's team at Pinterest found a way to parallelize much of it using Claude Code sub-agents.
The interesting part isn't that they used coding agents to speed things up. It's what they learned about which agent architectures work for this kind of task and which ones fall apart.
Before Claude Code (BC): the six-week grind
Faye described their old workflow, which is familiar to anyone who has done model training. It was a straightforward linear pipeline: define the data schema, clean and format it (JSON, Parquet), download a base model from Hugging Face, choose a fine-tuning method (LoRA, QLoRA, full fine-tuning), set up loss functions and reward parameters, run evaluations, iterate, and finally push the model to production. Once the model is live, they collect user preference data, and reinforcement learning techniques (DPO, PPO) are used for further alignment.
All of that, from start to finish, usually took four to six weeks. Much of it was sequential; you couldn't effectively run steps in parallel because each relied on the outputs from the previous stage.
The sub-agent approach: one week
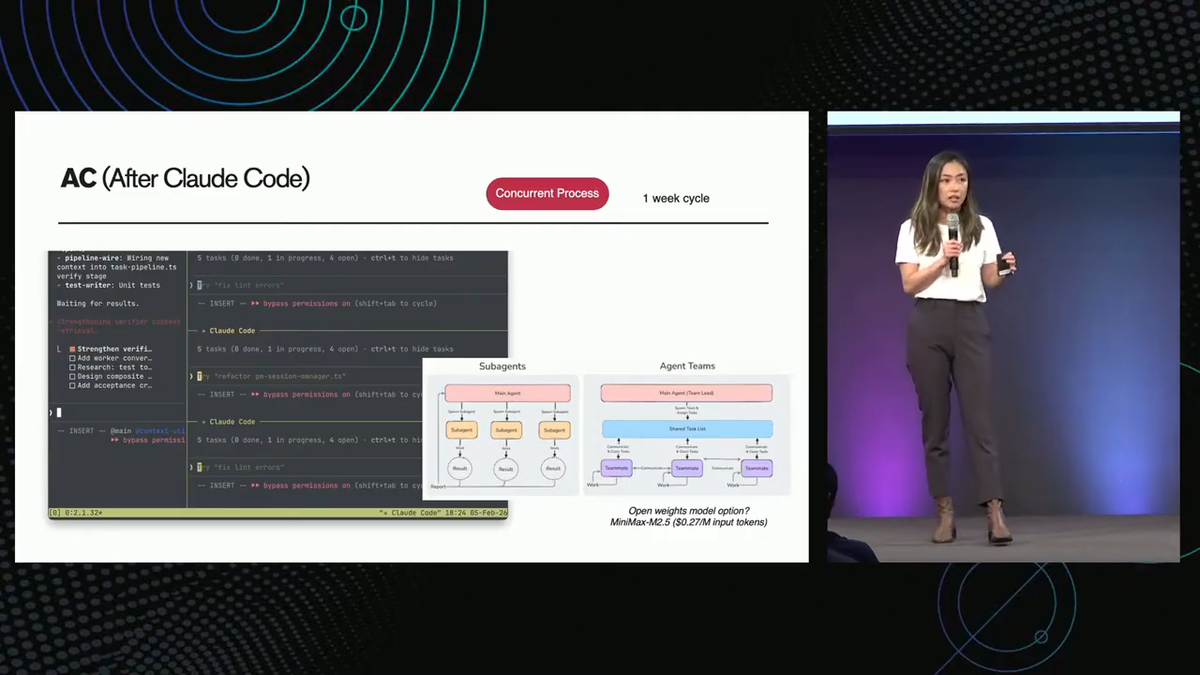
With Claude Code, Faye's team broke the pipeline into parallelizable tasks and assigned them to sub-agents. Data generation, SQL injection testing, training parameter configuration; these could all run concurrently under a main orchestrating agent rather than waiting in a queue.
But they didn't just jump to the most sophisticated architecture available. This is where the talk got interesting for me.
Why sub-agents are beating agent swarms (for now)
Faye's team evaluated two agentic architectures: sub-agents and agent swarms (also called agent teams); each has subtle distinctions. With sub-agents, each worker may communicate only with the main agent and reports back when their task is done. With swarms, agents share a task list, communicate with each other, and check on each other's work before collectively moving to the next stage.
Swarms sound more powerful on paper. However, Faye identified two bottlenecks that made them impractical for post-training workflows in practice:
- Context window explosion. Each agent keeps feeding its results to every other agent. The context window grows exponentially, and you hit limits fast.
- Orchestration rigidity. Claude Code doesn't support dynamic scaling of sub-agents. You run into what Faye called the "hot celebrity problem": one agent becomes a bottleneck, and there's no way to spin up additional workers to help it.
The sub-agent architecture avoids both issues by maintaining strictly hierarchical communication. It's less elegant but more reliable, which is usually preferred in a production training pipeline.
One practical note: Faye recommended MiniMax M2.5 as an alternative to Opus for sub-agent tasks, at roughly 27 cents on the dollar. It's trained on preference-alignment reinforcement learning (PRL), which she noted helps with dynamic sub-agent scaling; partially addressing the swarm architecture's second limitation if you're willing to mix models.
I've also written about how MiniMax and other open-weight models stack up against Opus. Worth checking out if you're interested in learning more about self-hosted models.
Four failure patterns to watch for
Even with the sub-agent architecture working, Faye identified four recurring failure modes in production:
- Spec drift. Over iterations of training, eval, and refinement, the agent framework loses track of what success actually looks like. The original metrics get diluted or forgotten.
- Data distribution bias. Faye called this the single biggest bottleneck. Uneven representation in training data leads to unstable training loss curves and unreliable model behavior. Agents generating training data can inadvertently amplify these imbalances.
- Memory collapse. After 20 to 100 training epochs, models start losing the ability to retrieve the right memory configurations from previous iterations. They begin hallucinating instead of building on prior work.
- Tool misuse. Less of an issue in 2026 than it was a year ago (the industry has gotten better at defining tool-use boundaries), but still something that requires monitoring.
What actually improved the pipeline
Two practical fixes stood out from the talk:
First, structured SKILLS.md files. Faye's team moved from natural-language instructions to more structured, machine-readable skill definitions for their agents. The more precise the instructions (including which hyperparameters to start with, or which validation steps to run), the better the agents were aligned with the intended process. She recommended the MS-Swift open-source framework as a starting point for teaching agents how to train LLMs.
Second, what Faye called "tool calling 2.0." Instead of the traditional pattern where an agent makes a request, gets a response, evaluates it, and makes another request (five round-trip requests for one task), they let agents write their own scripts to solve problems autonomously. The agent generates code, runs it in a loop until the output passes its own checks, and returns a single result. This cut token consumption by 50 to 70 percent.
That's a genuinely significant optimization. Most of the cost in agentic workflows comes from conversational round trips. Letting the agent collapse those into a single code-execute-verify loop is the kind of pattern that's become a best practice.
How I'm thinking about this
There's a broader point here that goes beyond Pinterest's specific pipeline. The question of how to architect multi-agent systems for production workloads doesn't have a settled answer yet, and Faye's talk was a useful data point because she tried both approaches and shared concrete results rather than theoretical preferences.
The sub-agents vs. swarms decision is one that I expect every team running multi-agent workflows will need to make for themselves. The right answer depends on your specific constraints: context window budgets, cost sensitivity and whether your tasks are truly parallelizable or have sequential dependencies. This is exactly the kind of architectural decision that benefits from the eval-driven approach rather than gut feel.
I was also struck by the memory problem Faye described. Memory collapse after extended training runs, and the open question of how to handle long-horizon development memory, feels like one of the more underexplored challenges in the agent ecosystem right now. She pointed to Cursor's hybrid retrieval approach using Merkle trees (the same data structure underpinning Ethereum's state management) and the Letta open-source project's approach of combining archive retrieval with vector databases. The two papers she highlighted on treating memory as a learned parameter (trained via GRPO) and hot/cold storage partitioning via MCP are worth paying attention to.
The tool calling 2.0 pattern is the takeaway I'm already applying; in fact, I wrote about this in my recent MCP isn't dead essay. Collapsing multi-turn agent conversations into single script-generation loops isn't a new idea, but seeing the 50-70% token reduction quantified in a production setting makes it harder to ignore. If you're running sub-agents that are burning through tokens on repetitive back-and-forth, this is probably your highest-leverage optimization.
What's next?
Watch Faye's full lightning talk. It's only nine minutes, and the density of practical insight per minute is unusually high for a conference presentation. If you're doing any kind of model training or fine-tuning with coding agents, the sub-agent architecture patterns and failure modes she describes will save you time.
Watch Faye's full lightning talk from Coding Agents 2026.
About the author

Derek Perez is the Founder & Principal Technologist of Limbic Systems, a software consultancy that partners with organizations to design and deploy AI-native software and systems — without losing the human judgment that keeps them grounded. After over a decade of hands-on experience building startups and leading high-performing teams at Google, he partners with founders and operators who need both technical depth and business acumen to navigate what's next. Find him on LinkedIn and Bluesky, or by email: derek@limbic.systems.