Three Agentic Open-Weight Models I'm Paying Close Attention to in March 2026
The open-weights ecosystem is exploding with innovation and unlocking a world of opportunity for agentic practitioners. But where do you start? Here's what has my attention.

At the moment, my go-to for agentic coding is Claude Opus 4.6 with Claude Code as my agentic harness. With that, I'm combining a select choice of MCP servers and a tight list of skills to keep things running smoothly (I'm a big fan of Obra's superpowers plugin). I'm really impressed with how much I can trust (but verify) the work it's capable of; life is good. However, like many people, I dread that the game of musical chairs our entire industry is playing with the AI behemoths and their supporting cast could come to an abrupt stop at any moment.
"The entire software engineering industry is claude-pilled, we're all opusmaxxing." - Derek (on a Zoom call)
I shudder to imagine the severe withdrawals nearly every software-powered business might face all at once. Many are unprepared or unable to pay the equivalent of a yearly salary to frontier model operators to keep their systems running. We already see a token subsidization gap between Anthropic's Max 20x plan and their API: for roughly the same number of tokens, using their API directly costs about 8-10 times more today. That is during the boom times. No frontier model operator is currently profitable, and while they hope to be around 2030, we don't know if the global economy will have the patience.
As we race toward an exciting and terrifying unknown future with AI, I remain optimistic that we'll continue to see big leaps in the open-weight models ecosystem, which will become crucial for maintaining the industry's continued productivity and growth expectations. While Anthropic is quick to point out that these advances might be stolen valor via Distillation, I don't find this ethically troubling if they're being paid for their tokens. After all, they distilled us, right?
Given this, here's my personal ranked list and analysis of the SOTA open-weight models worth paying attention to as of March 2026.
Opus-tier competition
These are my top three open-weight models worth considering if you need a model that's competitive with Opus 4.5/4.6 on agentic coding and research tasks. All of these models will require substantial hardware to achieve meaningful productivity gains.
MiniMax M2.5
MiniMax M2.5 is a 230-billion-parameter "Mixture-of-Experts" model from the Chinese AI lab MiniMax. It activates 10 billion parameters per token, achieving frontier-class coding performance at a fraction of the compute cost of dense models. Its defining achievement is matching Claude Opus 4.5 on SWE-bench Verified — the industry's primary agentic coding evaluation — while running entirely on prosumer-grade hardware.

Key points of interest
- 230 billion total parameters, MoE with 256 experts, 8 experts active per token = 10 billion active parameters.
- Lightning Attention enables a native (theoretical) 1-million-token context (practical operational window: 200,000).
- Trained via Forge — proprietary RL framework across 200,000+ real-world environments (code repos, web browsers, Microsoft Office). Uses CISPO algorithm, ~2× faster than ByteDance's DAPO, ~40× training speedup via tree-structured sample merging.
- Achieved an 80.2% on SWE-bench Verified, and a 55.4% on SWE-bench Pro. Additionally, MiniMax claims it achieved a 76.8% score on the BFCL Multi-turn benchmarks, but this has not been confirmed on the official leadboards. Among all open-weight models in this article, M2.5 scores highest on these 3 benchmarks.
- Text-based input and output only; no native vision or multimodal support.
Running this model
It's fairly straightforward to get this model running on your own hardware. Unsloth has a helpful llama.cpp-based guide, or you can run it with MLX on Apple Silicon. As for the hardware requirements, Q4 (~115GB) fits on a single H200, and Q6 (~172GB) also fits on one. BF16 (~460GB) would require VRAM capacity, but Q4–Q6 offers near-full-quality throughput. For hardware-specific quantizations, check out the lmstudio-community repo on HuggingFace. Or check out Unsloth's Dynamic 2.0 quants, which are currently outperforming other providers on accuracy.
GLM-5
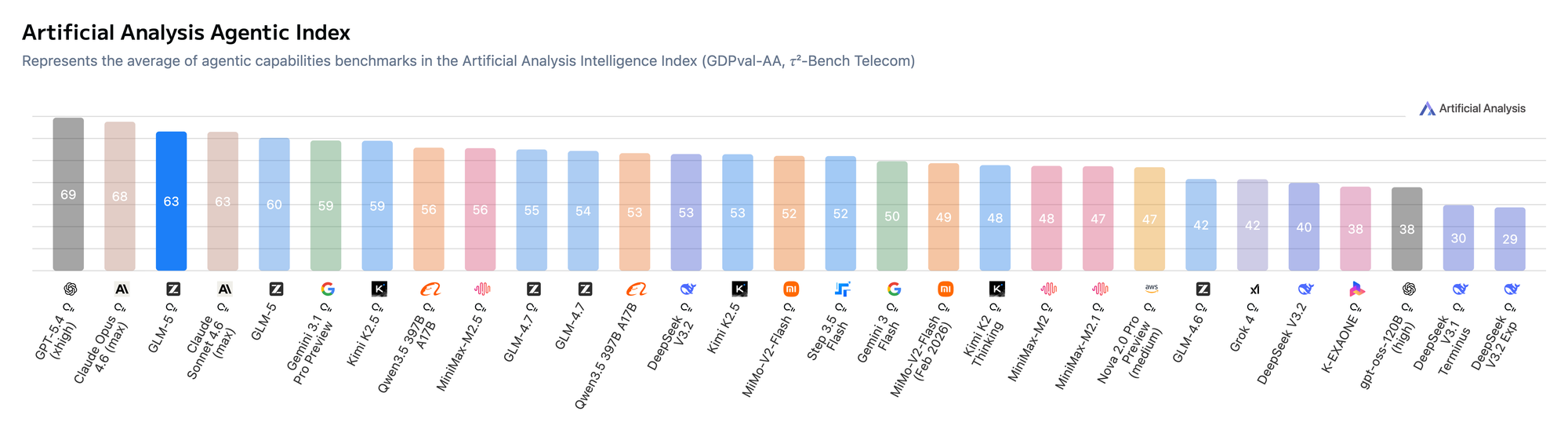
GLM-5 is a 744-billion-parameter "Mixture-of-Experts" model from the Chinese AI lab z.AI (Zhipu AI). It activates 40 billion parameters per-token across 256 experts — a far heavier active footprint than the others — in exchange for exceptional reasoning depth and the lowest hallucination rate in the open-weight ecosystem. It was trained using a novel reinforcement learning infrastructure called Slime. GLM-5 is the first open-weight model to score 50 on the Artificial Analysis Intelligence Index, placing it just behind Opus 4.5. However, for the Agentic Index variant of this benchmark, it sits right between Opus 4.6 and Sonnet 4.6.
Key points of interest
- 744 billion total parameters, MoE with 256 experts, 8 regular experts + 1 shared expert active per token = 40 billion active parameters. The heaviest active footprint of any model in this article. It's a direct tradeoff for its reasoning depth.
- Uses Multi-head Latent Attention (MLA) combined with DeepSeek Sparse Attention (DSA), which dynamically allocates compute based on token importance with a context window partitioned as 200,000 tokens in / 128,000 tokens out.
- Trained via Slime — an open-source asynchronous RL infrastructure that decouples trajectory generation from gradient updates, enabling massive-scale long-horizon agent training without synchronization bottlenecks. The APRIL system within Slime reduces GPU idle time by up to 44% by handling long-tail generation inefficiencies.
- Achieves a -1 on the AA-Omniscience Index, representing a 35-point improvement over its predecessor and the lowest hallucination rate of any model in this article.
- Scores 77.8% on SWE-bench Verified, and 73.3% on SWE-bench Multilingual. This makes it second among open-weight models on both benchmarks.
- Text-based input and output only; no native vision or multimodal support.
Running this model
GLM-5's weights are released under the MIT license. However, GLM-5 is the most hardware-constrained model you could deploy today. The full BF16 model requires 1.65TB of disk space. Z.AI's suggested production path is the FP8 checkpoint, which cuts that roughly in half, but still requires a minimum of eight H200 or H20 GPUs operating in a unified cluster with high-bandwidth interconnects. Unsloth also provides its own quantizations on HuggingFace, which may introduce accuracy tradeoffs.
Kimi K2.5
Kimi K2.5 is a 1.04-trillion-parameter "Mixture-of-Experts" model from Moonshot AI, activating 32 billion parameters per token across 384 experts, making this the largest expert pool of any model in this article. Unlike the others, it was co-trained on 15 trillion mixed visual and text tokens, making it inherently multimodal rather than vision-adapted afterward. Besides being multimodal, its key feature is Agent Swarm: the ability to self-direct up to 100 sub-agents, executing 1,500+ parallel tool calls simultaneously, thanks to its innovative training method, PARL (Parallel-Agent Reinforcement Learning). On the SWE-bench Verified benchmark, it scores 76.8% and currently ranks 47 on the Artificial Analysis Intelligence Index, making it the second-highest open-weight score, behind GLM-5.

Key points of interest
- 1.04 trillion total parameters, MoE with 384 experts, 8 active per token = 32 billion active parameters. The largest expert pool of any model in this article, with 50% more experts than the 256-expert configurations used by GLM-5 and MiniMax M2.5.
- Uses Multi-head Latent Attention (MLA), compressing key-value projections into a lower-dimensional space before computing attention scores, cutting memory bandwidth by 40–50%, and enabling efficient long-context inference supporting a context window of ~256,000 tokens.
- Trained using the MuonClip optimizer, purpose-built for stable trillion-parameter MoE training. The full 15.5-trillion-token pretraining run completed without a single loss spike (a major engineering achievement for this model at this scale).
- Scores 76.8% on SWE-bench Verified and 50.7% on SWE-bench Pro. Ranks 47 on the Artificial Analysis Intelligence Index, coming in second among open-weight models behind GLM-5's 50.
- Natively multimodal, unlike the other models in this article, meaning it can work with images and multimedia. K2.5 was co-trained on 15 trillion mixed visual and text tokens, using a 400M-parameter MoonViT vision encoder.
Running this model
Kimi K2.5's weights are released under a modified MIT license. Compared to the others we've discussed, the self-hosting story is far more accessible. K2.5 was released natively in INT4 precision via Quantization-Aware Training; INT4 is the full-fidelity checkpoint, not a compressed approximation. That brings the base disk footprint to approximately 600GB. That's large, but not a significant burden. vLLM and SGLang both support deployment, and Unsloth provides GGUF quantizations down to a 1.8-bit dynamic variant at ~240GB — small enough to run on a single 24GB GPU with MoE layers offloaded to system RAM, though at reduced throughput. For comfortable GPU-resident inference at full INT4, you'll want a handful of H200-class GPUs (similar to GLM-5's deployment needs), without the penalty of first quantizing from BF16.
What's next?
It's interesting to explore the similarities among these agentic-grade models and their individual differences. All three models share the same core architecture: Mixture-of-Experts, with active parameter counts in the tens of billions rather than hundreds. MiniMax M2.5 activates 10 billion parameters, Kimi K2.5 activates 32 billion, and GLM-5 activates 40 billion. Yet all three compete directly with frontier models that use every available parameter for each token; this tradeoff makes them feasible for self-hosting.
However, their differences reveal a lot. M2.5 shows it is the top performer in coding: with the highest SWE-bench Verified score of the three, the most accessible hardware requirements, and the longest practical context window. GLM-5 sacrifices deployment ease for superior reasoning depth and consistency: it has the largest active footprint and the lowest hallucination rate among open-weight models. It ranks highest on the Artificial Analysis Intelligence Index. Kimi K2.5 takes a different approach: it's the only one among the three designed as a natively multimodal model, and its Agent Swarm feature embodies the most ambitious parallel agentic execution of any open-weight model released so far.
When working with self-hosted models, it's essential to evaluate our use cases carefully before investing. This isn't usually a consideration when working with frontier models. We sometimes compare Haiku, Sonnet, and Opus and often integrate their capabilities seamlessly as subagents for specific tasks within a coding harness like Claude Code. With self-hosted models, it's unlikely you'll be running multiple (self-hosted) models together, so selecting the right one for each task will require testing and experimentation. Have fun!
About the author

Derek Perez is the Founder & Principal Technologist of Limbic Systems, a software consultancy that partners with organizations to design and deploy AI-native software and systems — without losing the human judgment that keeps them grounded. After over a decade of hands-on experience building startups and leading high-performing teams at Google, he partners with founders and operators who need both technical depth and business acumen to navigate what's next. Find him on LinkedIn and Bluesky, or by email: [email protected].