Evals Are How Serious AI Practitioners Ship Without Vibes
There's a gap between teams that ship AI features based on gut feel and teams that actually know whether their system is working. Most teams are on the wrong side of it and don't realize it yet.
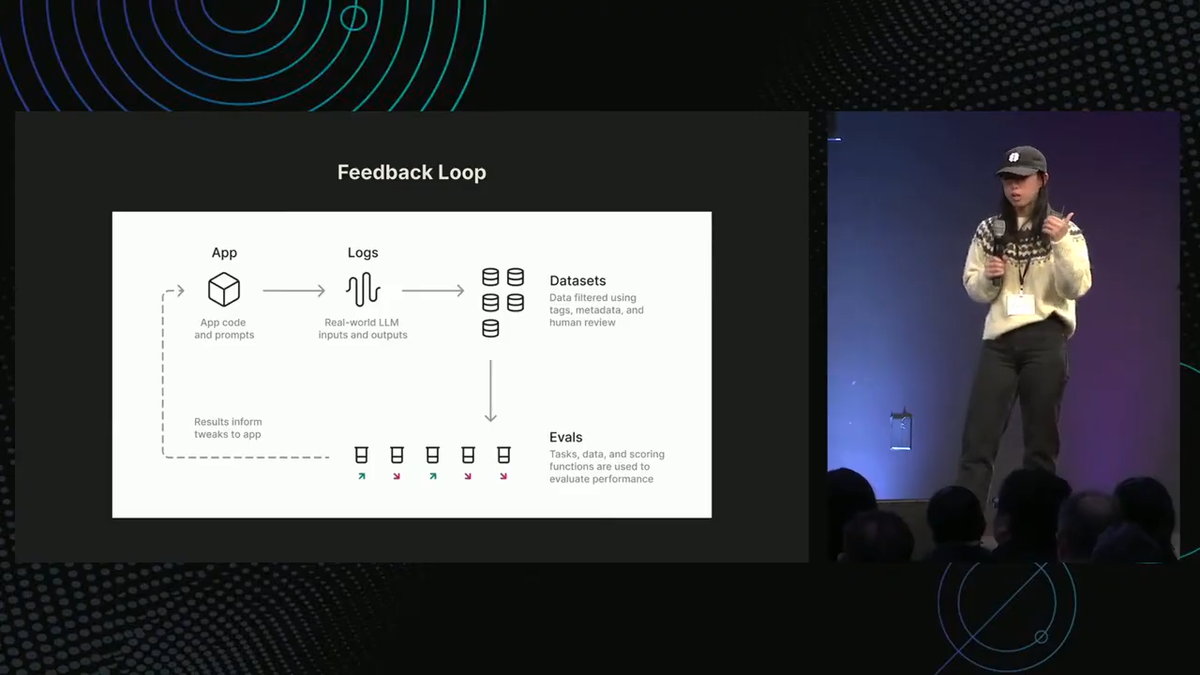
Jessica Wang from Braintrust recently spoke at the Coding Agents 2026 conference in Mountain View, CA. Her talk stood out to me because it laid bare something I've been thinking about for a while: the gap between teams that ship AI features based on gut feel and teams that actually know whether their system is working.
Jessica described experiences with teams shipping AI features because an engineer said it was ready, or because a PM tried a few prompts and it "looked good." That's vibe shipping at its best, and it's exactly the kind of practice that serious AI practitioners avoid.
Evals are the mechanism that bridge this gap, and her talk made a compelling case for why they matter by walking through a real, non-trivial eval she ran comparing agentic search against vector search (RAG) for coding agents.
Why evals matter
Running evals lets you quantify shipping decisions instead of hand-waving them. Instead of "it looks good," you get statements like: "We ran 200 different test cases and 94% of them passed." Or, more usefully, nuanced observations like: "This change improved tone but decreased accuracy by 5%."
Jessica outlined several questions that evals are uniquely positioned to answer: which LLM is the best choice for a given use case (especially when new models drop), how the system performs across diverse real-world scenarios (Python vs. TypeScript codebases, English vs. Japanese inputs), whether you can achieve high performance without excessive costs, and most critically: how you know when something breaks or gets worse.
In April 2025, OpenAI had to revert an entire model update because changes intended to make the model more helpful actually made it too agreeable and therefore less useful. That's the kind of regression that evals are designed to catch before it ships.
The anatomy of an eval
Jessica broke the eval process into four components, which I found to be a clean and practical framework:
- Dataset: A collection of test cases including golden use cases, edge cases, and failure modes. These are the inputs your system will be tested against.
- Task: The definition of how your system should behave when processing an input. This is typically a prompt paired with a specific model in mind.
- Scoring: The criteria that determine whether the AI's output is good or bad. This can be deterministic scoring, LLM-as-a-judge, or human review. The person writing the scorer must define what "good" means.
- Experimentation: One run of a specific configuration (dataset + task + scorer) equals one experiment. As you test different hypotheses and tweak your system, each variation becomes a new experiment run that you can compare against previous ones.
One point Jessica made that really resonated with me: evals are a team sport. AI engineers bring data and make code changes, PMs develop hypotheses and define success criteria, subject matter experts help label data and tweak prompts (especially in deep knowledge domains like medicine, law, or insurance), and data analysts define scores and analyze results. No single person owns the whole loop.
The eval: agentic search vs. vector search
The meat of the talk was a real eval Jessica ran to compare agentic search against vector search for coding agent tasks. The motivation came from Cursor's public discussion of how semantic (agentic) search significantly improved their coding agent performance, and the broader online discourse about which approach is actually better.
For those unfamiliar, vector search converts code into numerical embeddings that capture semantic meaning, chunks them, and stores them in a vector database. When queried, it finds the closest embeddings to your question. Agentic search is what coding agents like Claude Code are using, typically as CLI tools (ripgrep, find, ls, cat), and reads through code the way humans would: searching for function names, opening files, following references, and tracing logic chains.
Experiment design
Jessica built two datasets to test across different languages and codebases:
- Microsoft's TypeScript-Go repo: Pulled merged PRs with "fix" in the title, checked out the parent commit (putting the codebase in a known buggy state), then used Claude to synthesize bug descriptions from the PR diffs. The Go test suite served as the pass/fail criterion.
- SWEBench Verified (Django subset): 25 rows from the industry-standard benchmark that Anthropic and OpenAI use to evaluate their models. Same concept: known bugs with known fixes.
The agentic search variant testing was simple. Claude Code uses agentic search by default, so they just pointed it at the tasks. The vector search variant, on the other hand, was trickier to test. They implemented a basic vector search script and had to actively prevent Claude Code from falling back to agentic search, which it desperately wanted to do. This required using explicit techniques like Claude Code's disallow_tools flag to block CLI tools like grep/find, etc., plus explicit prompting to use the vector search script exclusively.
The results
On SWEBench (Django): vector search scored 60% accuracy, agentic search scored 68%. On TypeScript-Go: both scored 70%. However, the cost and token usage provided a more stark comparison: vector search consumed significantly more tokens and cost considerably more per run.
Jessica is quick to point out that the absolute cost numbers from this eval didn't really make sense; however, the relative differences measured between the two approaches were still meaningful.
What the traces revealed
The raw scores are interesting, but the real insights came from digging into the traces. Three patterns emerged:
Vector search gave proximity without connective tissue. It returns chunks of code that might be near the relevant area but lack the surrounding context (imports, type definitions, calling code, etc.). The agent doesn't get enough signal for what else to look for. In one SWEBench run, the agent made 26 different vector search calls, essentially hunting and pecking around because it couldn't conclusively detect where the bug originated.
Agentic search enables chain-of-thought exploration. The agent can find a function, read the entire file top to bottom, see the import chain, follow references to other files, leverage LSPs, and trace the logic. It navigates code the way an experienced developer would. Vector search, by contrast, can't follow those threads.
More searches mean more cost. The reason vector search burned so many more tokens is straightforward: the agent kept making calls because it couldn't pinpoint the bug. Agentic search found the right place faster and spent fewer resources doing it.
This eval isn't done, that's the point
I appreciated Jessica's intellectual honesty here. She explicitly said she wouldn't publish a blog post about these results, because the eval isn't rigorous enough, yet! Her own gut sense was that the results overstated the agentic search's advantage. She outlined four areas she'd improve:
- Run multiple trials per task: LLMs are non-deterministic. She wouldn't be surprised if repeated runs of the exact same configuration swung results by 10–15%. Averaging across trials is essential.
- Improve the vector search implementation: The baseline was basic. Chunk overlapping, better splitting strategies, and retrieval models could close the gap.
- Test a hybrid approach: Many companies are now combining vector search and agentic search. That's worth evaluating independently.
- Expand the dataset: With only 10 rows in one dataset, a single failure swings the score by as much as 10%. More rows, more languages, and more codebases would make the results more meaningful.
This is exactly the kind of disciplined thinking that separates eval-driven teams from vibes-driven ones. The point isn't to get a definitive answer from your first experiment run — it's to build a measurement system that you refine alongside your product.
How I'm thinking about this
Jessica's talk reinforced something I've been increasingly convinced about: serious AI practitioners must rely on evals to get the most out of models for agentic tasks. It's also a critical step to qualify potential new models and ensure existing production deployments are retaining their efficacy in the field.
Every time a new model drops, the question isn't abstractly "is it better?" It's "is it better for our specific use cases, against our specific dataset, measured by our specific criteria?" (How Aristotle of me) Evals are the only way to answer this with confidence. Without them, we're vibe deploying.
And it's not just frontier model releases. As I explored in my recent look at open-weight models worth watching, the same discipline applies when evaluating whether workloads can be adapted onto self-hosted infrastructure. The cost and performance tradeoffs of running a MiniMax M2.5 or GLM-5 versus Opus for your specific agent tasks aren't something you can eyeball; that's an eval.
The observability angle is equally important. Jessica showed how to leverage Tracing with Claude Code & Braintrust, where every LLM call and CLI execution is logged. That level of visibility is what lets you understand why something failed, not just that it did. For anyone running agentic systems in production, that distinction is non-negotiable.
There's also a timely connection here to the MCP vs. CLI debate I wrote about: as agentic systems increasingly start mixing protocol-based tool calling with direct CLI access, evals become an essential mechanism to track which approach actually delivers better results for specific task types over time, rather than arguing from hypothetical first principles.
I also found the production feedback loop she described at the end to be a solid mental model: log live (properly redacted/processed, of course) production data, sample a percentage of it into a dataset, write evals against that dataset, learn from the results, and ship improvements back to the app from eval qualifications. It can become a continuous improvement loop that gets better over time, and it's the kind of operational rigor that compounds.
What's next?
Watch Jessica's full presentation; the walkthrough of the actual experiment design, trace analysis, and results is worth your time, especially if you're building with coding agents or are ready to evaluate eval frameworks (lol).
Watch Jessica's full presentation from Coding Agents 2026.
About the author

Derek Perez is the Founder & Principal Technologist of Limbic Systems, a software consultancy that partners with organizations to design and deploy AI-native software and systems — without losing the human judgment that keeps them grounded. After over a decade of hands-on experience building startups and leading high-performing teams at Google, he partners with founders and operators who need both technical depth and business acumen to navigate what's next. Find him on LinkedIn and Bluesky, or by email: [email protected].